
Die Diskussion rund um künstliche Intelligenz dreht sich oft um eine einzige Frage: Welches Modell ist gerade das beste?
Welche KI führt die Benchmarks an? Welches Modell schlägt die Konkurrenz bei Coding, Reasoning oder komplexen Agenten-Workflows?
Für Unternehmen ist jedoch eine andere Frage viel wichtiger:
Welches Modell ist gut genug für meine konkrete Aufgabe – und was kostet es, dieses Modell zuverlässig zu betreiben?
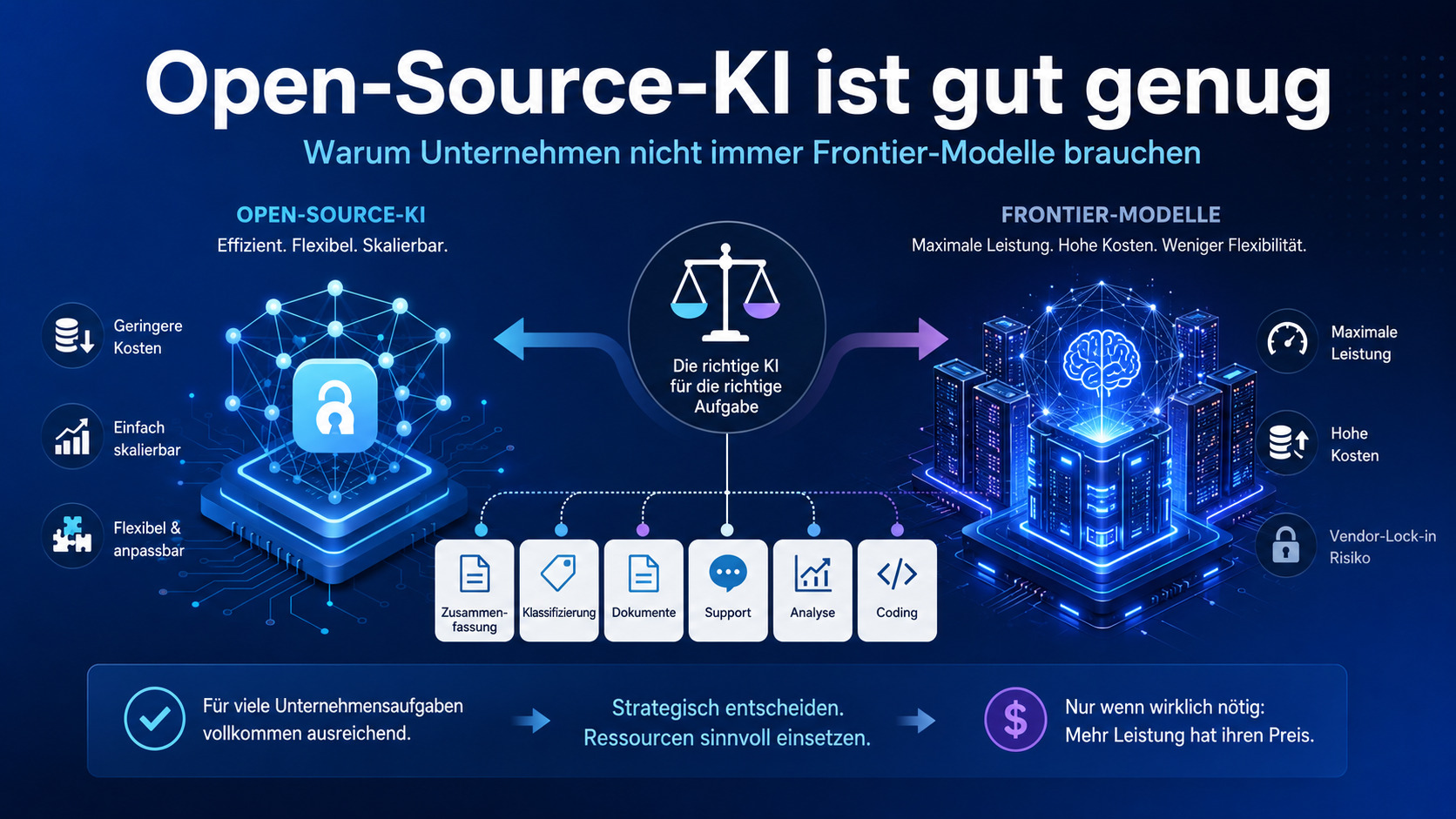
Genau hier beginnt ein Umdenken. Denn viele Organisationen zahlen heute für KI-Intelligenz, die sie in dieser Form gar nicht benötigen - und kommen zu der Überzeugung: Open-Source-KI ist gut genug!
Der Abstand zu Frontier-Modellen existiert – aber er ist nicht immer entscheidend
Open-Source-Modelle liegen bei anspruchsvollen Aufgaben weiterhin hinter den leistungsstärksten proprietären Frontier-Modellen. Besonders bei komplexem Software Engineering, Cybersecurity-Aufgaben oder langen mehrstufigen Reasoning-Ketten haben die besten geschlossenen Modelle klare Vorteile.
Das bedeutet aber nicht automatisch, dass jedes Unternehmen für jede KI-Aufgabe ein Frontier-Modell einsetzen sollte.
Viele produktive KI-Anwendungsfälle sind deutlich einfacher:
- Zusammenfassungen
- Klassifizierungen
- Datenextraktion
- Übersetzungen
- Kundenservice-Routing
- Dokumenten-Q&A
- erste Text- oder Codeentwürfe
Für diese Aufgaben braucht es häufig nicht die letzten zehn Prozent Modellleistung. Es braucht ein Modell, das stabil, schnell, ausreichend korrekt und bezahlbar skalierbar ist.
Der Denkfehler: Jede Aufgabe bekommt das stärkste Modell
Viele Teams behandeln KI-Modelle so, als gäbe es nur eine relevante Kennzahl: maximale Intelligenz.
Das ist teuer.
Nicht jede Aufgabe verlangt komplexes Reasoning. Manche Aufgaben sind im Kern Mustererkennung, Umformulierung oder strukturierte Extraktion. Dafür ein teures Frontier-Modell einzusetzen, ist oft so, als würde man einen Supersportwagen kaufen, um zum Briefkasten zu fahren.
Sinnvoller ist eine Einteilung nach Reasoning-Bedarf.
Drei Kategorien für KI-Aufgaben
1. Niedriger Reasoning-Bedarf
Diese Aufgaben sind überwiegend standardisiert, wiederholbar und gut eingrenzbar.
Beispiele:
- Dokumente zusammenfassen
- E-Mails kategorisieren
- Informationen aus Formularen extrahieren
- Texte übersetzen
- einfache Entwürfe aus Briefings erstellen
- Support-Tickets weiterleiten
Hier sind Open-Source-Modelle in vielen Fällen völlig ausreichend. Der Mehrwert eines teuren Frontier-Modells ist oft gering, während die Kosten deutlich höher ausfallen.
2. Mittlerer Reasoning-Bedarf
Diese Aufgaben erfordern mehr Kontextverständnis, mehrere Zwischenschritte oder eine Ausgabe, die fachlich belastbar sein muss.
Beispiele:
- Code auf Korrektheit prüfen
- Berichte aus mehreren Quellen erstellen
- komplexe juristische oder technische Dokumente analysieren
- längere Gespräche mit Kontext führen
In diesem Bereich können Open-Source-Modelle ebenfalls konkurrenzfähig sein. Entscheidend ist jedoch, eigene Tests mit den eigenen Daten durchzuführen. Benchmarks geben Orientierung, aber sie ersetzen keine Evaluation im realen Anwendungskontext.
3. Hoher Reasoning-Bedarf
Hier spielen Frontier-Modelle ihre Stärken aus.
Beispiele:
- autonome Coding-Agenten in großen unbekannten Codebasen
- Research-Agenten, die viele Quellen auswerten und logisch verknüpfen müssen
- sicherheitskritische Analysen
- komplexe Agenten-Workflows mit vielen Tool-Aufrufen und Fehlerkorrekturen
Für diese Aufgaben kann der Leistungsunterschied geschlossener Spitzenmodelle tatsächlich entscheidend sein.
Kosten sind nicht nur ein Detail – sie verändern die Strategie
Der Preisunterschied zwischen Frontier-Modellen und Open-Source-Alternativen kann erheblich sein. Selbst wenn ein Frontier-Modell leistungsfähiger ist, stellt sich die Frage:
Ist es so viel leistungsfähiger, dass es ein Vielfaches der Kosten rechtfertigt?
Bei vielen Standardaufgaben lautet die Antwort: wahrscheinlich nicht.
Gerade bei hohem Volumen summieren sich Tokenkosten schnell. Ein Unternehmen, das tausende Mitarbeitende mit KI-Coding-Tools ausstattet oder große Mengen an Kundenkommunikation verarbeitet, kann innerhalb weniger Monate Budgets aufbrauchen, die ursprünglich für ein ganzes Jahr geplant waren.
Deshalb lohnt sich ein hybrider Ansatz:
Frontier-Modelle dort einsetzen, wo sie wirklich gebraucht werden – und günstigere Open-Source-Modelle dort, wo sie ausreichend gute Ergebnisse liefern.
Das unterschätzte Risiko: Abhängigkeit von einem Anbieter
Kosten sind nur ein Teil des Problems. Ein zweiter wichtiger Punkt ist Vendor Lock-in.
Wer seine KI-Infrastruktur vollständig auf einen einzigen kommerziellen Anbieter stützt, macht sich abhängig von dessen:
- Preisen
- Verfügbarkeit
- Richtlinien
- Account-Entscheidungen
- technischen Änderungen
Was passiert bei einer Preiserhöhung?
Was passiert bei einer API-Störung?
Was passiert, wenn ein Account fälschlicherweise gesperrt wird?
Solche Risiken wirken abstrakt, bis sie den laufenden Betrieb treffen. Dann ist es zu spät, erst mit Alternativen zu experimentieren.
Warum Unternehmen jetzt testen sollten
Der beste Zeitpunkt, Open-Source-Modelle zu evaluieren, ist nicht während einer Krise. Der beste Zeitpunkt ist dann, wenn noch kein Druck besteht.
Ein kleiner Test mit einer internen, nicht-kritischen Aufgabe kann bereits wertvolle Erkenntnisse liefern:
- Wie gut funktioniert ein Open-Source-Modell mit unseren Daten?
- Wo liegen die Qualitätsgrenzen?
- Welche Aufgaben lassen sich günstig routen?
- Welche Aufgaben brauchen tatsächlich Frontier-Leistung?
- Welche Infrastruktur müssten wir aufbauen?
Diese Experimente kosten vergleichsweise wenig, schaffen aber strategische Flexibilität.
Frontier-Modelle bleiben wichtig – aber selektiv
Die Botschaft ist nicht, Frontier-Modelle abzuschaffen. Sie sind bei schwierigen Aufgaben weiterhin führend und können enormen Mehrwert schaffen.
Die eigentliche Frage lautet:
Setzen wir sie gezielt dort ein, wo sie notwendig sind – oder verschwenden wir Budget für Aufgaben, die auch günstigere Modelle erledigen könnten?
Für viele Unternehmen wird die Zukunft nicht aus einem einzigen Modell bestehen, sondern aus einem intelligenten Routing-System:
- einfache Aufgaben an günstige Modelle
- mittlere Aufgaben an geprüfte Open-Source- oder kleinere kommerzielle Modelle
- kritische Aufgaben an Frontier-Modelle
So entsteht eine KI-Architektur, die leistungsfähig, kosteneffizient und robuster gegenüber Ausfällen oder Preisänderungen ist.
Fazit: Gut genug ist oft besser als maximal intelligent
Die wichtigste Frage für Unternehmen lautet nicht:
Welches KI-Modell ist absolut das beste?
Sondern:
Welches Modell ist für diese konkrete Aufgabe ausreichend gut, zuverlässig genug und günstig genug, um nachhaltig zu skalieren?
Für viele produktive KI-Workloads zeigen Open-Source-Modelle bereits heute, dass sie mehr als nur eine Alternative sind. Sie sind ein strategischer Hebel gegen steigende Kosten, Abhängigkeiten und unnötige Komplexität.
Wer jetzt beginnt, eigene Tests aufzusetzen, baut sich Optionen auf, bevor sie dringend benötigt werden. Und genau diese Optionen können später den Unterschied machen.
Enter your text here...